Wir hatten große Probleme bei der Konvertierung eines PDFs mit Finereader zum Word-Dokument.
Letzten Endes haben wir es abgeschrieben, es war schneller als die OCR Fehler zu korrigieren, der Text war zerhackt, alle Buchstaben standen auch in der Höhe kreuz und quer und waren in unterschiedlichen Farben:
Quelle PDF vom Scan:

Nach der Konvertierung zum Word:

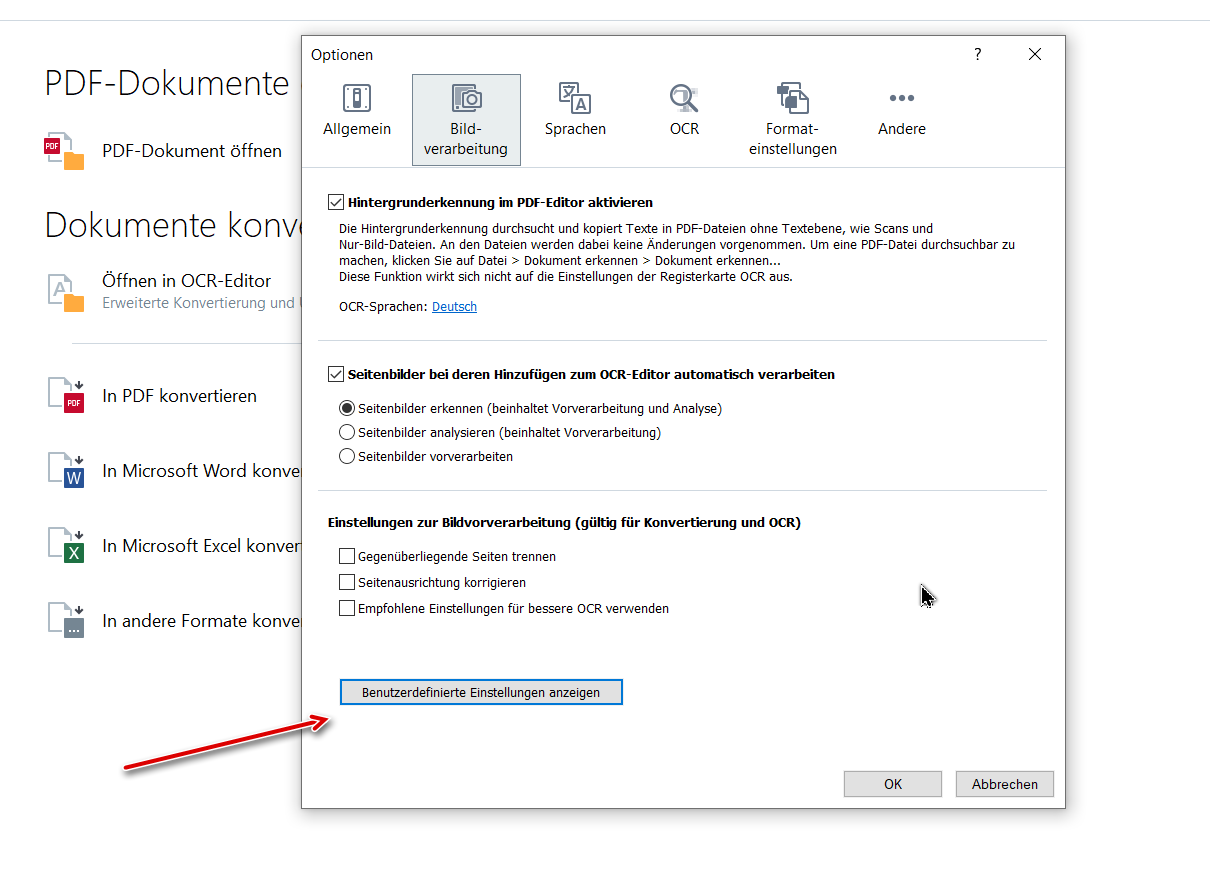
Im Nachgang habe ich mit dem ABBYY Suport gesprochen und man sagte uns, dass ich die Verarbeitung irgendwelcher Hintergrundbilder verhindern soll. Das haben wir getan und schwups … wir hatten ein brauchbares Word-Dokument:

Hier der Rat des Supports auf Englisch:
1. Please remove hidden text and objects in a PDF document as described in the article: Removing hidden text and objects in a PDF file in FineReader PDF and save the document.
2. Open FineReader PDF and disable image preprocessing settings as described in the article: How to disable image preprocessing in FineReader PDF.
3. Open the redacted PDF in OCR Editor > select German as recognition language > recognize it > save in Word format.
zu 1.
Für FineReader PDF 16:
Gehe zum Sicherheits-Tab > klicke auf die Schaltfläche „Objekte und Daten löschen“.
Für FineReader PDF 15:
Klicke auf den Pfeil neben der Schaltfläche und wähle „Objekte und Daten löschen“ aus.
Im sich öffnenden Dialogfeld wähle die zu löschenden Objekte und Daten aus und klicke auf „Anwenden“.
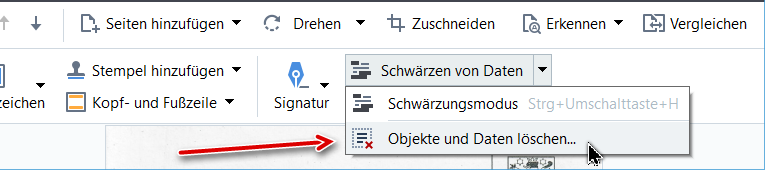

zu 2.